
AI 导读
这篇文章讲述了作者在进行项目采集时遇到的挑战,尤其是代理服务器的重要性。由于系统故障,作者丢失了几天的代码,导致情绪低落。但他> 决定继续进行代理服务器的采集工作。
主要内容:
- 代理服务器的必要性:在网络采集中,使用代理可以避免被封锁。
- 获取代理:作者推荐了利用在线资源获取免费代理IP和端口,特别提到了hidemyass.com网站。
- 数据采集方法:使用JavaScript和jQuery在浏览器控制台抓取数据,最初的尝试遇到了显示与隐藏的HTML元素问题。
- 处理隐藏元素:由于需要过滤掉隐藏的标签,作者探讨了使用Java的jsoup库进行DOM解析和数据抓取的方式。
- CSS解析:为了解决隐藏元素的问题,作者实现了一个简单的CSS解析器,用于识别哪些类是隐藏的,从而提取有效的IP地址。
整篇文章既包含了技术细节,也展示了解决问题的思路和方法。
关键词:代理服务器、数据采集、jsoup
吐槽
昨夜突发一级事故,写了几天的项目,由于死机蓝屏,修复还原,把数据盘都给弄坏了,丢了几天的代码。来的太突然,到现在还没缓过劲来,郁闷死我了。其中也包括本篇将要介绍的东西,本来准备昨天发的。
开始
搞过采集的同学都知道,有一样东西不可少,Proxy! 是的,如果说用了代理跑的慢的话,不用代理,呵呵,直接被K了。其重要性不言而喻。今天碰到的问题恰好和代理有关系。
最近由于项目需要,要做点采集工作,本着自己不动手也能丰衣又足食的精神,找找了现成的,其实也不用找,大家比较熟悉的产品应该是“火车头”吧。界面复杂,功能强大,支持代理,自带了代理管理器。有了此神器,采集工作如虎添翼。等等,你得先有代理服务器啊……
代理的获取可以是多种多样的,黑阔同学可以用手中的小肉鸡子,土豪可以自己多找几个黑阔,那么屌丝怎么办?表急,网上搜搜先。我们开开Google大神,输入 “Free http proxy server”,怎么样,是不是有了?你喜欢哪个我不知道,我反正点开的是 hidemyass.com,是不是很屌?
图1.Home of HideMyAss.com
来来,围观一下,有在线代理,匿名邮件,呃,功能有点多,我们只要Proxy Server IP 和 Port 。 选择 “IP:Port Proxy”,来到了 Proxy Server List 页面,
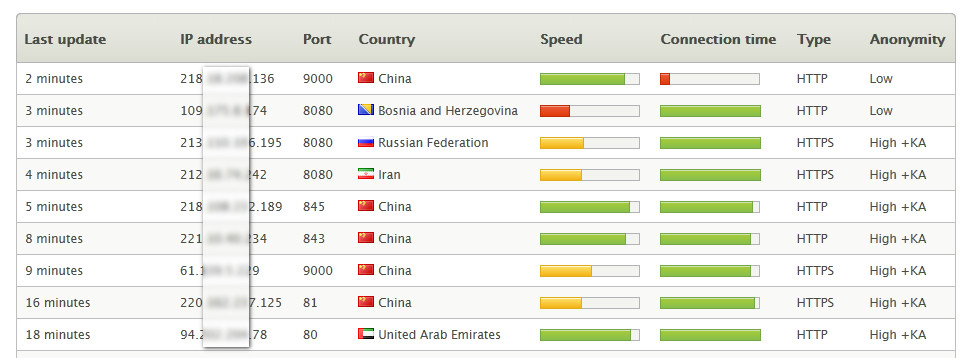
图2. Proxy sever list
(有人说楼主是骗纸,网页根本打不开呀!) (擦,此站和类似的其他网站需要翻墙)
鼠标键盘操作利索的话,这一页几十条数据也是妥妥的复制好。可是,服务器列表不是死的啊,会更新啊,难道要重新再猛击鼠标键盘?懒人推动了世界的进步,这个我一点都不怀疑。首先我想到偷懒的方法,也是我的一惯做法,直接页面注入JS采就完了。说来就来,Chrome里,我果断的按下了”F12″。啪啪啪地敲下了下面的JS(现敲的,昨天的全丢了),
图3. jQuery Test in Chrome
呃,好的,用了 jQuery,省得自己注入了,继续,目测,IP和PORT分别是第1栏和第2栏,
var _html = [];
$('#listtable tbody tr' ).each(function(i, n){
var _line = [];
var _self = $(this);
//var tds = _self.find('td')
_line.push(_self.find('td:eq(1)').text());
_line.push(_self.find('td:eq(2)').text());
_html.push(_line.join(':'));
})
console.log(_html.join('\n'));
代码清单1
好激动呀,眼看着就要得手了,
.UBXR{display:none}
.rcBy{display:inline}
.wikF{display:none}
.wECt{display:inline}
4545188218.18140.208.66136:
9000
.UbG7{display:none}
.odO4{display:inline}
.uK-0{display:none}
.cvKi{display:inline}
.CiSC{display:none}
.azWI{display:inline}
109156156.585877939595130130130175184184184196196211.6668232929187187246.8888135135135136174240:
8080
.j05u{display:none}
.A5AR{display:inline}
.X9qd{display:none}
.qnVe{display:inline}
.ylFA{display:none}
.V_RW{display:inline}
.eqQH{display:none}
.Wfut{display:inline}
505093121213214214.110147147.23232632515161188196203203.133154195:
8080
代码清单2
纳尼?What?神码东西,乱的一塌糊涂啊!
请出神器,一探究竟,
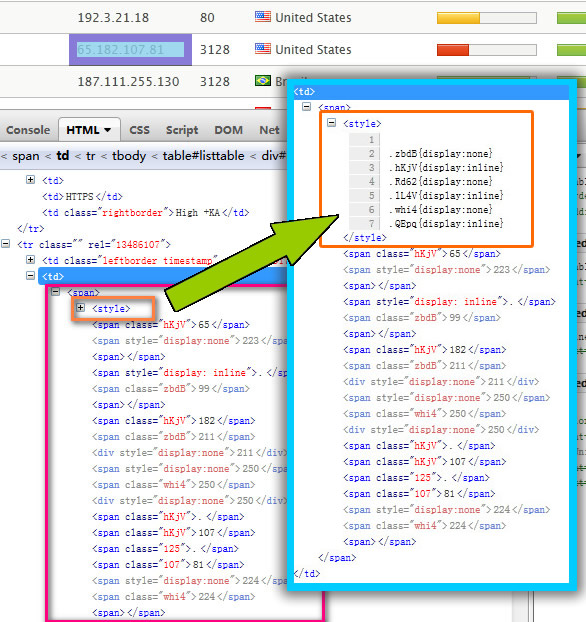
图4. Ip 单元格 DOM 情况
丧心病狂有木有?本来想夸夸这个网站界面清爽没广告呢(某些国内站点呀,满屏牛皮癣,恶心不),看来我想多了 –!! 肿么办?裤子都脱了,当然不能放弃治疗啊。既然都已经在浏览器环境了,咱就模拟一下浏览器,让人看见的留下,看不见的删除,这不就有了嘛,继续,
var _html = [];
$('#listtable tbody tr' ).each(function(i, n){
var _line = [];
var _self = $(this);
//var tds = _self.find('td')
var td = _self.find('td:eq(1)');
td.find('style,span:hidden,div:hidden').remove(); //注意这里
_line.push(td .text());
_line.push(_self.find('td:eq(2)').text());
_html.push(_line.join(':'));
})
console.log(_html.join('\n'));
代码清单3
再看看控制台,
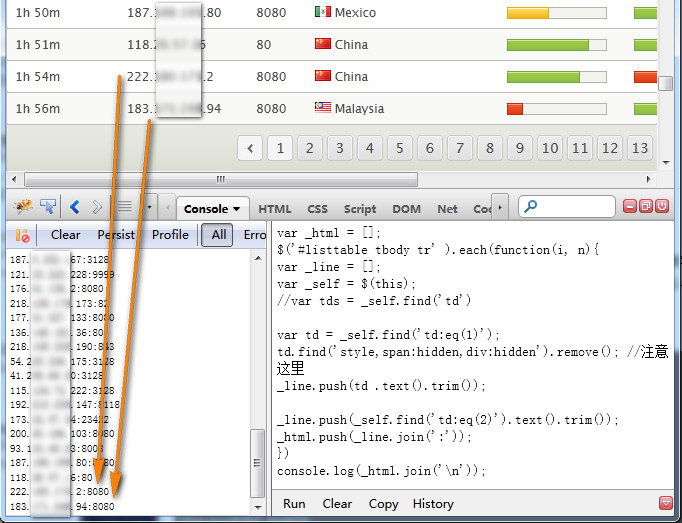
图5. 采集正常啦
搞定!
至于健康判断啦,连接速度判断神码的,留给您自己发挥吧。
本来行文到这里就差不多了,采集任务已经顺利完成,可是最近写长文有点上瘾,而且要紧的,咱们不能对自己要求这么低,是不是?浏览器控制台采集最多属于半自动,临时应个急还行,每次刷行,还得手工执行代码、拷贝结果、导入结果,恶心。咱们来往前再迈一步,看看完全自动化的方案是怎么样的。
进阶
假如我们现在需要自己整一个Proxy Server List 抓取器,毫无疑问,还是从此网页抓取,和之前一样的流程。有一个不一样的地方,是什么呢?
浏览器里面,我们可以通过使用 jQuery 来轻易判断 span啊 div啊 是隐藏的还是显示的,而不用理会他是因为使用 还是使用 。可是咱们 Java 哪里会理解呢?累觉不爱呀。
用 Java 来解析 HTML 内容常用方法无非是 JDOM之类的DOM解析工具,按部就班。或者呢,使用HTMLParser这样的库,最棒的是他提供了CSS Selector来选择DOM 节点。或者,你要是熟悉 jQuery 的话,可以像我一样,用一用 jsoup 。jsoup 不是 soup, 是一个牛逼的、使用 jQuery 选择器(也就是 Sizzle http://sizzlejs.com/) 语法 (参看 http://jsoup.org/cookbook/extracting-data/selector-syntax),让Java操作DOM Node 也能犹如 JS 般自由痛快。唯一遗憾的是,她不能识别 “:hidden” 伪类,而恰恰正是本例需要的一个重要特性。
让我们来一个例子看看,下面是IP单元格的HTML源码,

代码清单4. 加密混淆后的IP单元格
真是大开眼界呀(这下,某东呀,某程呀,防采集又有新思路啦) 。看着这一坨,我瞬间有了很多想法,这是一种人机的区分方法啊,机器不可读,人可识别,这不就是个验证码么?我甚至还想到一条面试题,假如给你这么一坨,你能一口说出来,屏幕上显示的是什么么?擦,反正我是不行啦。
为了从这一坨里面找出真正的IP地址,我们需要过滤很多的噪音标签。最容易的一种就是类似 <div style="display:none">76 这样的,jsoup里面节点操作只需一句就可以搞定 ele.select('div[style*=none]') 。 在DOM节点转文本之后,标签不用理会,不会当作文字输出,真正要操心的是什么呢?仔细看最开头,竟然插入了一个 style ,动态定义了哪些标签是显示的,哪些是隐藏的,所以,我们需要知道哪些 class 是隐藏,哪些 class 是显示。这不就是浏览器根据 CSS 来 显示 HTML 的过程么?擦,原来不知不觉,咱也学会浏览器核心原理啦 ^^
俗话说解铃还得系铃人,CSS的问题还得按照浏览器的思路来做。jsoup 已经为我们扫清了第一步障碍,可以直接确定的干扰标签就直接删了,剩下的,jsoup也无能为力,只能靠自己啦。按照CSS的思路,我们需要解释一下style里面的内容,知道哪个是 class, 哪个 class 是隐藏功能。由此看来,我们需要一个CSS解析器。
这个解析器,功能不需要全,不用识别复杂的选择器,只要是识别 class ,识别 class 是隐藏的就好了。至于如何实现,见仁见智,你要是正则大牛,一条正则搞定,就当我没说。除此之外,咱们今天就来用一用 JDK 自带的宝贝: StreamTokenizer 。这个东西是什么,基本用法之类的请诸位直接谷歌之,这里就不赘述了,直接上干货,下面就是我写的 CssStreamTokenizer 主要代码,
static class CssStreamTokenizer extends StreamTokenizer {
public CssStreamTokenizer(Reader r) {
super(r);
this.resetSyntax();
this.wordChars(0, 255);
this.ordinaryChar('.');
this.ordinaryChar('#');
this.ordinaryChar('{');
this.ordinaryChar('}');
}
static final int CSS_EOF = -0x01;
static final int CSS_BLOCK = -0x02;
static final int CSS_CLASS = -0x04;
static final int CSS_ID = -0x08;
static final int CSS_UNKNOWN = -0x10;
boolean isOutClass = true;
boolean isOutId = true;
boolean isOutBlock = true;
static final Pattern P_CLASS = Pattern.compile("^[a-zA-Z][\\w\\-]*");
static final Pattern P_ID = Pattern.compile("^[a-zA-Z][\\w\\-\\:]*");
public int nextCSS() {
int token;
try{
switch(token = this.nextToken()){
case StreamTokenizer.TT_EOF:
return CSS_EOF;
case '{':
//进入标记字段
isOutBlock = false;
return nextCSS();
case '}':
isOutBlock = true;
isOutClass = true;
isOutId = true;
return nextCSS();
case '.':
isOutClass = false;
return nextCSS();
case '#':
isOutId = false;
return nextCSS();
case StreamTokenizer.TT_WORD:
if(!isOutId && isOutBlock && P_ID.matcher(sval).find())
return CSS_ID;
else if(!isOutClass && isOutBlock && P_CLASS.matcher(sval).find())
return CSS_CLASS;
else if (!isOutBlock)
return CSS_BLOCK;
else
return CSS_UNKNOWN;
default:
return CSS_UNKNOWN;
} //end of case
}catch(IOException e){
System.out.println("Error:"+e.getMessage());
}
return CSS_UNKNOWN;
}
}
代码清单5
CSSStreamTokenizer 的主要功能就像他的名字一样,把 CSS 一串字符串,按照语法切分成语法的组成部分,可以得到 CLASS 、 ID和具体内容。利用 CSSStreamTokenizer 可以轻易的分析一串 CSS 中,哪个 class 是 hidden的,接着看下面的 Parser,
static class CssParser {
static final Pattern P_HIDDEN_CSS = Pattern.compile("display\\s*[\\:]\\s*none");
private String html;
CssParser(String html) {
this.html = html;
}
public String[] getHiddenClasses() {
if (html == null || html.length() == 0)
return null;
CssStreamTokenizer tokenizer = new CssStreamTokenizer(new StringReader(html));
int token = 0;
boolean inCSS = false;
Stack stack = new Stack();
while ((token = tokenizer.nextCSS()) != CssStreamTokenizer.CSS_EOF) {
String sval = tokenizer.sval;
if (token == CssStreamTokenizer.CSS_CLASS) {
System.out.println(">>CLASS");
inCSS = true;
stack.push(sval); // push first
}
else if (token == CssStreamTokenizer.CSS_ID) {
System.out.println(">>ID");
}
else if (token == CssStreamTokenizer.CSS_BLOCK) {
System.out.println(">>BLOCK");
if (inCSS && !P_HIDDEN_CSS.matcher(sval).find()) {
stack.pop(); // pop it, not hidden class
}
inCSS = false;
} else {
System.out.println(">>UNKNOWN");
inCSS = false;
}
System.out.println(tokenizer.sval);
}
return stack.toArray(new String[]{});
}
}
代码清单6
好的,Parser 更进一步,化繁为简,直接提取了 HiddenClasses,到了这里,只要jsoup里来这么一句 ele.select("className").remove() ,恭喜你,烦人的噪音咩有啦!
全文完,谢谢观赏,请拍砖。
ZD 2014-01-05
(本站文章均为原创,侵权必究)